A Replication Study to Assess the Ability of LSTMs to Learn Syntax-Sensitive Dependencies
This project was a study to replicate the results of a paper by Linzen et al. titled “Assessing the Ability of LSTMs to Learn Syntax-Sensitive Dependencies”. This was submitted for the final project as part of the CS388 Natural Language Processing course at UT Austin. The original paper can be found here.
Before I talk about the project, I would like to provide a small introduction to Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs).
What are RNNs?
Recurrent Neural Networks use sequential data to solve temporal (time-based) and ordinal (location-based) problems. This commonly includes natural language processing problems such as translation and prediction, and also audio and video processing problems.
Recurrent Neural Networks can be thought of as chain of cells where each cell maps to a different word in a sentence, or a different frame in a video, etc. However, it is modeled using a single cell where the weights for the same cell are updated in a loop. The weights of the RNN are refined through every cell’s output with the use of Backpropagation Through Time (BPTT), which factors in the error in the cell’s prediction for each time step in the network’s loop.
However, RNNs can run into two similar problems: exploding gradients and vanishing gradients. Exploding gradients occur when the backpropagated error keeps increasing exponentially because of large errors in the loop. Vanishing gradients occur when the backpropagated error keeps decreasing exponentially to zero because of very small errors in the loop. Both are problematic because one makes the model unstable while the other makes the model useless (zero weights). These issues are more likely to arise when the inputs to the model are very long.
Different architectures including Long Short-Term Memory networks (LSTMs) and Gated Recurrent Unit networks (GRUs) were introduced to combat these gradient issues that arise with the use of simple RNNs.
What are LSTMs?
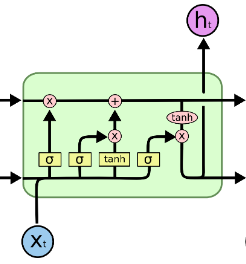
LSTMs are a type of RNNs that can deal with long-term dependencies in the inputs. If important context information to the current step in the loop is not in the recent past, a simple RNN may lose the gradient and not make a good prediction.
LSTMs introduce a new type of cell that has an input gate, an output gate, and a forget gate. The forget gate is new functionality introduced to eliminate unimportant states from the network’s overall cell state. This allows more important context information to remain relevant over a long-term dependency in the input.
Our project
As mentioned before, our project was to replicate the results of a paper by Linzen et al. that demonstrates LSTMs can understand syntax-sensitive dependencies. While this result lines up with the reasoning behind the use of LSTMs, we wanted to verify their results and expand upon their ideas.
The authors of the original paper implemented their models using an older version of Keras. However, being more familiar with the PyTorch library, a major part of our paper replication project was to utilize their source code to understand what results were produced by what models and then translate the models into PyTorch accordingly.
The problem used to evaluate the ability of LSTMs to learn syntax structure was the Number Prediction Task. In this task, the model is supposed to predict the number (plurality) of the upcoming verb in the sentence given the sentence up to and not including the verb. This may be a hard problem because of several reasons outlined in our paper, including intervening nouns and verbs.
We used the dataset created by Linzen et al. to evaluate our models. We ran several experiments including predicting the plurality of the verb by just providing the nouns leading up to the verb, just providing the POS (Part of Speech) tags of the nouns leading up to the verb, and even providing the wrong labels to observe if sentence context is being utilized.
We also replicated a self-supervised learning model from the Linzen et al. paper that uses just the previous words in the sentence to predict the next word. No syntactic context is provided to the model directly i.e. the model doesn’t explicitly know the plurality of the nouns and the verbs.
In our paper replication study, we showed that our results majorly aligned with those of Linzen et al. However, we were not fully convinced that their methodology captured the full ability of LSTMs. So, we proposed two extensions to their paper that can provide more insight into LSTMs. The first extension was to randomize the subject in the sentence while keeping the verb the same. The second extension was to probe our number prediction model using a different task (POS tag prediction) to understand whether the model was actually capturing syntax information. Our results suggested that the model was in fact capturing syntax and context information.
You can read our paper to get more insight and explanation for our results!